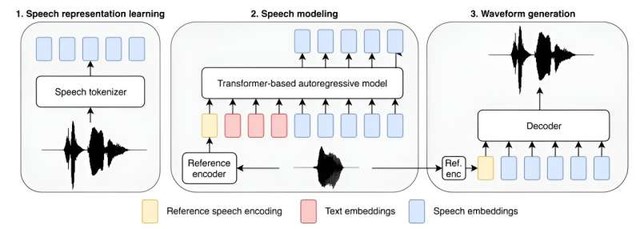
亚马逊人工智能研究团队近日宣布开发了一款据称是史上最大的文本转语音模型。该模型拥有9.8亿个参数,并使用了10万小时的录音数据进行训练,其中大部分为英语语音。研究人员向模型提供了其他语言的单词和短语示例,使其能够正确发音一些常见的表达。
研究人员还测试了使用较小数据集的模型,希望能从中发现人工智能领域所说的“涌现能力”。他们发现,对于文本转语音应用而言,这种飞跃发生在参数量达到1.5亿的中型数据集上。
研究团队指出,出于对潜在滥用风险的担忧,BASE TTS将不会向公众开放,他们计划将其作为学习应用,并期望将学到的知识应用于改善文本转语音应用的整体音质。
这项研究对于推动人工智能技术在主流应用领域的融入具有重要意义。随着越来越多的大型语言模型被开发出来,人们对于AI助手、聊天机器人等方面的需求也在不断增加。然而,在推广这些技术之前,我们需要确保它们的安全性和可靠性,并采取适当的措施来防止滥用。
因此,研究团队表示,BASE TTS模型将不会向公众开放,并计划将其用于学习应用。同时,他们还希望通过提高文本转语音应用的音质和准确性,帮助人们更好地使用这些技术。
此外,在开发和训练文本转语音模型时还需要考虑其他因素。例如,如何处理不同语言之间的差异、如何增加模型的多样性以提高其适应性等等。只有通过综合考虑这些因素并不断改进技术,我们才能实现真正智能和可靠的人工智能系统。
本文属于原创文章,如若转载,请注明来源:史上最大语言模型来了:拥有9.8亿个参数https://dcdv.zol.com.cn/856/8561698.html